Matt Sheehan is a fellow at the Carnegie Endowment for International Peace, where his research focuses on China’s artificial intelligence ecosystem. He is the author of a recently published paper, China’s AI Regulations and How They Get Made, the first report in a three-part series that explores how the Chinese government is formulating rules to rein in the country’s burgeoning AI sector. He spoke to The Wire a few weeks after Chinese regulators published their interim regulations in July on generative AI, the kind of algorithms like ChatGPT that can be used to generate content. In this lightly edited Q&A, we discuss Matt’s research process, how China’s AI regulations compare with those in the West, and what those new rules for generative AI mean for China’s competitiveness in the global AI race.

Illustration by Lauren Crow
Q: In tracing the evolution of China’s AI regulations in your report, you’ve also told a story of how events and ideas become legislation — almost “how a bill becomes law, China edition”. Could you talk about your research process and how you pieced together that chronology?
A: I had this idea a long time ago that I want to trace a policy from its very roots all the way up until it becomes finalized, and then back down to how it’s implemented — sort of the life cycle of a policy or regulation. And I ended up applying that methodology to the AI regulations because it seemed important to see exactly who and what is feeding into these regulations, and then how they get actualized on the ground. That’s going to impact everything from U.S. businesses, to political systems in the global south, to large, scalable AI risks and all that.
I started out with one question: how does China make AI regulations? From close reading the regulations themselves, I would find terms that stood out as not just standard boilerplate, and seemed like something that could be traced backwards. I focused on the draft recommendation algorithm regulations that came out in September 2021, and one thing that stood out in them was the decision to focus on recommendation algorithms (算法推荐 suànfǎ tuījiàn).1Algorithms used to recommend content to users, a widespread practice on social media platforms like TikTok and Instagram. It was an odd selection for a very first piece of AI or algorithm regulation. Recommendation algorithms are omnipresent, but they’re also so diffuse in their applications and not usually thought of as pertaining to the core issues in AI ethics. So I got curious about that, and found a couple of threads that I could trace backwards.
| BIO AT A GLANCE | |
|---|---|
| AGE | 35 |
| BIRTHPLACE | Chicago, Illinois, USA |
| CURRENT POSITION | Fellow, Asia Program, Carnegie Endowment for International Peace |
One was just the term“算法推荐” [suànfǎ tuījiàn, or “recommendation algorithms”]. When did that term first appear in state media or in the public discourse, and how did it evolve over time? I found there was a clear point in mid-2017 when the People’s Daily ran a series of three op-eds on three consecutive days lambasting recommendation algorithms for all the social ills that they bring about. Within those op-eds, you could see that they were clearly targeting Jinri Toutiao, ByteDance’s news recommendation app, an earlier ByteDance app that existed long before Douyin or TikTok. You could see that the core of their concern was the dissemination of information online. So starting from there, I traced it through state media and Chinese think tanks to see how their ideas around recommendation algorithms — and the threat they pose to the CCP’s information controls — evolved into a central policy concern that eventually got elevated to the Central Committee; and then how it filtered back down to Chinese policy think tanks, and eventually into the form of a CAC [Cyberspace Administration of China, the top internet regulator] regulation.
The core concern behind these regulations is control over information. And that is a tale as old as time for the CCP.
What I found pretty interesting is that there were other provisions in it that didn’t really seem to fit. One that really stood out was the decision to include worker scheduling algorithms2Algorithms that assign deliveries to gig workers and determine how quickly they must make them. under the algorithmic recommendation regulation. That was odd. I guess they could be called recommendation algorithms in a way, in that they recommend a route and a price, but that’s pretty different from personalized news recommendation algorithms. When you trace that one backwards, you can pretty clearly see that it originated from a massive public outcry from a viral magazine exposé about the way that algorithms were contributing to the exploitation of delivery drivers.
| MISCELLANEA | |
|---|---|
| FAVORITE BOOK | King of the World: Muhammad Ali and the Rise of an American Hero by David Remnick |
| FAVORITE PERFORMER | Kendrick Lamar, but I still haven’t seen him live. |
| FAVORITE FILM | Toy Story |
| MOST ADMIRED | “Most admire” is a tough one, but growing up and throughout my 20’s I would always be asking myself if what I was doing was as interesting and exciting as what my dad was doing at that same age. |
So from these two cases, you have two things coming from almost the opposite end of the system. One is very much core Party concerns, transmitted through Party media, and worked through Party think tanks and government bodies; and on the other side you have a non-state media magazine, writing a long exposé detailing the plight of delivery workers, leading to a huge public outcry that then pressured the regulators into working this into that same regulation covering recommendation algorithms.
It sounds like regulators’ priorities are motivated by incidents that are quite specific to a Chinese context. Does that mean that Chinese regulators have focused on different issues when it comes to AI compared to regulators in the West?
I’d say it’s both. In some cases, it’s incident-driven, and in some cases, it’s long-standing Party interests applied to the world of AI. The core concern behind these regulations is control over information. And that is a tale as old as time for the CCP. Then you have other events in the world that either add to those regulations, or drive the development of new regulations.
In a lot of cases, those CCP concerns do have a mirror in Western concerns about AI. We both talk about misinformation and fake news, and we both talk about the threat of deep fakes. In some ways we’re talking about the same larger issues, but we have way different structures within our societies to adjudicate that. For China, misinformation is anything other than what the Party agrees to. When we talk about misinformation, we’d like to think that it’s slightly more objective, or not tied to the specific political concerns of the ruling party.

While that can lead to very different regulations, in some cases, it does actually lead to pretty similar responses. The most direct one is the regulation on what Chinese regulators call “deep synthesis,” which is really generative AI with another name. That regulation was finalized in late 2022, and one of the provisions that is reinforced in the [2023] generative AI regulation is that you have to label AI generated or AI augmented content. Now you’re seeing Chinese tech companies work this into their actual products. For example Douyin has released a public policy and a technical standard for how they are going to visually watermark AI-generated content, and to technically watermark it in a way that can be detected by other algorithms. And that’s a very popular international idea. The White House recently released its agreement with leading AI companies, and included in it is an agreement to work on watermarking AI-generated content. So in some ways we do have a dramatically different system than China, and our push against misinformation is not the same as theirs; but in other cases we do end up landing in similar places in terms of regulatory interventions.
One interesting detail you mention in the paper is how companies like Tencent have a role in influencing AI rulemaking, as shown in one example where Tencent lobbied to replace the more charged term ‘deep fakes’ with the term ‘deep synthesis’. How did Tencent go about doing that, and how much of a role do private sector companies play in AI rule making in China?
That was a pretty clear example of where industry lobbying or industry thought leadership led to a concrete change in the nature of a regulation. Pretty much at the same time that the Chinese government had started talking about recommendation algorithms as a threat, they also started talking about deep fakes as a threat.


Tencent Cloud offers a paid service allowing clients to create high-definition digital humans using just three minutes of live-action video and 100 spoken sentences. Credit: Tencent
Around that same time, industry and the Tencent Research Institute in particular were getting uncomfortable with the idea of regulating “deep fakes”, because it is clearly a very negative term, and the regulations would almost certainly include a much broader scope of technical interventions. Snapchat and all its filters and the Chinese equivalent, Meitu — all these Chinese apps that do augmented reality in some way, using AI or using algorithms — probably fall under the purview [of ‘deep fakes’]. But it’s not strictly correct to call them deep fakes. And so the Tencent Research Institute and others in the industry started putting out reports and events talking about how ‘deep fakes’ is too narrow a term, and that we really should start using this term, ‘deep synthesis,’ which includes most of what we would call generative AI.

We can’t fully peer behind the curtain and know how that backroom lobbying took place, or how receptive the regulators were to this. But the fact is, when the regulators did finally come up with the draft regulation, they adopted the term ‘deep synthesis’ that had been introduced by industry. This is not to say that Tencent tricked the party into using its term, or that it used old school lobbying to get what it wanted. Deep synthesis is actually a better term than deep fakes. But it’s an interesting example of where companies can intervene in the world of ideas, where scholars and think tanks and thought leaders are all kind of contributing to an intellectual stew that ends up getting shaped into a regulation by the actual bureaucracies.
In terms of generalizing more about how companies in general lobby around this, or how they assert their interests, that’s tough to know because most of that happens in places we just don’t have insights into, and it also varies a lot with time. If you were in mid-2021, that was a time when the regulators weren’t really trying to hear it from the tech companies, and they had a very free hand to smack them down. Maybe that balance has shifted somewhat, given the Chinese government is much more concerned about the economy and enabling economic growth. Now they’re much more interested in working with the companies to hash out what is an acceptable set of regulations that balance the growth imperative with regulatory demands.
In mid-July the CAC released its interim regulations on generative AI. You’ve noted that the regulations are much more relaxed than the draft version. What are some of the changes? And why do you think the authorities loosened their grip?
The draft regulations were extremely stringent, and just not very realistic. The most clearly unrealistic provisions were the ones that said all of the training data needs to be “true and accurate,” and all of the outputs from generative AI need to be “true and accurate.” And that’s just not feasible given that you’re essentially training these models on a huge chunk of the Internet, and what they’re outputting has very well documented problems of hallucination, where they make things up or they get things wrong, and there’s no clear technical path towards ensuring that they are 100 percent accurate.
One very clear way that they relaxed these rules is that they changed those from saying the training data and the outputs must be true and accurate, to saying they must take effective measures to increase the truth and accuracy of the training data and the outputs. So instead of saying it must be, it’s saying you must make reasonable efforts to improve. That alone is a huge lightening up of the requirements. It gives the companies a lot more breathing room to try to explore the space and to try to put products out without worrying that one false step could bring the regulators down on them.
The other provision that is pretty important is the narrowing of the scope of what’s covered. The original draft regulation included research and development and any internal uses of generative AI by companies and institutions. And it also covered public facing uses of generative AI — things like ChatGPT that allow the public to interface with the product directly and generate outputs themselves.
The final regulation narrowed that scope and got rid of the research and development, and got rid of the internal company uses. And they left behind only generative AI services that are facing the public in mainland China. There’s still a little bit of fuzziness around that and what exactly it means to have public facing services. It clearly includes things like ChatGPT, but would it include generative AI tools that are used to create something that ends up being public facing, but that the public can’t interface with themselves? But excluding research and development and excluding purely internal uses of generative AI is a huge thing that lets a ton of the ecosystem develop without fear of regulatory crackdowns.
From the Party’s perspective, one of the top priorities is using AI to upgrade the economy and to upgrade their political and social infrastructure. And all of that should remain outside the bounds of these regulations.
Do the loosened rules allow Chinese generative AI developers to be more competitive with the West? Or are there still going to be things holding them back?
They’re definitely still more regulatorily constrained than competitors in the U.S. or Canada or Europe. But this takes a huge burden off them when it comes to proving that their products are politically safe. It allows researchers and labs to have almost free rein with this stuff. And it allows companies to build and deploy these tools internally. It’s saying: if you want to create your equivalent of ChatGPT and have it facing the public, then you’re going to have to meet these regulatory demands. That is a meaningful part of the generative AI ecosystem. It’s certainly the most high profile part at this point in time, but it also might not prove to be the most important.

From the Party’s perspective, one of the top priorities is using AI to upgrade the economy and to upgrade their political and social infrastructure. And all of that should remain outside the bounds of these regulations. If you’re a law firm, and you want to use generative AI to draft contracts, that’ll save you a ton of time, and that’s fully allowed. Companies always need to be concerned about what the government thinks about what they’re doing, and it’s true that at some point in time, the winds could change, and they could decide that, for example, Baidu violated X, Y and Z political red lines when it released ERNIE Bot. That does make companies more cautious and build in more safeguards. But I don’t think they’re going to be completely smothered by this regulation.
In your report, you write that despite Xi’s reputation for micromanaging certain policy areas, there is little evidence that he’s done so with China’s AI regulations so far. What led you to that conclusion?
The people in China involved in this area that I’ve spoken to describe it the same way: Xi Jinping is not weighing in on the details of deep synthesis regulation and content watermarking requirements. That’s way below his radar, and requires a much more fine tuned policy response. State media has not described Xi as involved, which it sometimes does for other areas. Maybe most importantly the regulations so far do not bear the hallmark of a classic Xi intervention, which usually means taking a very hard line and potentially unrealistic policy stance that prizes control and Xi’s other priorities over everything else. The bulk of this work so far has gone down in a world that is ideologically and politically guided by Xi at a very high level, but not one in which he is in the weeds.
How did the Chinese government develop the knowhow to understand the sector and regulate it? Do you think that the regulators have enough expertise to regulate this area effectively?
Two points on that. The first one is the regulators are very much feeling their way through this. They are simultaneously regulating and learning how to regulate. They’re imposing requirements on the companies and then figuring out if the companies can meet those requirements, or if those requirements are even what is needed to achieve their goal. So it’s not like they came in with a perfectly clear vision and a deep understanding of the technology itself and then went from there. The Chinese phrase I would use is 看着办, kind of “do it while we’re looking.” That’s very much the approach they take here.

When it comes to the actual drafting and reviewing of the regulations, they lean heavily on expert committees. The CAC leans heavily on expert committees (专家委员会). And these are usually composed of academics, technical people either from companies or from research labs, and legal scholars who all contribute to these areas. The legal scholars are often people involved in tech law, maybe were involved in drafting the Cybersecurity Law and other areas. They’ve built up an expertise in data and other issues. They serve on these committees or are sometimes seconded to the CAC. And from those positions, they help draft the regulations in some cases, or comment on and revise them. It’s a pretty well functioning system, in the sense that there’s no way that people within CAC can have the full technical or legal background and the ability to integrate it all.
Turning to Chinese versus Western approaches to AI regulation — you make this distinction between horizontal and vertical approaches to AI rulemaking. Could you talk a little bit about the difference between the two and how that affects the way that regulation is being developed in China and the West?
The highest level of distinction in terms of how you’re going to regulate AI usually comes down to this horizontal versus vertical regulation. Horizontal is a broad regulation that’s intended to encompass nearly all applications of a given technology. This is exemplified by the European Union’s AI Act. It’s supposed to be the AI Act, covering nearly all applications of AI, which involves getting the whole regulatory apparatus built in one go.
China is taking the opposite approach, with a series of vertical regulations. Vertical regulations target one application, or maybe a group of related applications, and then try to come up with regulatory interventions that specifically address that, without trying to solve the whole problem in one go.
The EU has the one AI Act, and China already has three different regulations on recommendation algorithms, deep synthesis and generative AI. Maybe this is a philosophical difference or just a process difference, but it does have a huge impact on what interventions and what level of specificity you’re going to go into with those interventions. And neither approach is going to be purely horizontal or purely vertical. The EU AI Act — even though it’s one AI Act to rule them all — is going to use technical standards to get more specific about how to deal with different applications of AI. So it’s broadly horizontal, but it’s got some vertical elements.

The Chinese regulations are very vertical, but in that process, they’re building up horizontal tools that work across all three regulations. So for example, they built the algorithm registry, which is basically an online system for disclosure around algorithms, what data they’re trained on, and whether they use biometric characteristics. Anyone who has an algorithm in one of these regulated applications needs to fill out their algorithm registration. And so while that was created by one regulation, it’s been reused in deep synthesis and by generative AI regulations. That lightens the load for regulators, so they don’t have to reinvent the wheel with every new vertical regulation. It also lets them refine that tool over time.
So in the long run, do you see the two approaches converging, with Chinese and Western AI regulation having more common ground?
Yeah, they’re probably headed in that direction. China has now released three vertical regulations, but the State Council also announced that they are going to begin working on a draft AI law. The Chinese approach mirrors their approach to regulating the Internet, which is to write a lot of specific vertical regulations dealing with specific problems, building up your understanding and your expertise, and then when the system is ready, then you put a capstone law on top of it, which in this case, would be the national AI law. So that’s one way that the Chinese approach might be getting more horizontal over time.

With the EU AI Act, at the level of legislation, it’s very horizontal in that there’s one massive law that needs to be passed. But as they get into actual implementation of it, they’re going to have to build out a lot more specific verticals, standards and requirements for different applications in order to make it tractable and feasible. So they might be sort of headed towards a similar place, but on very different paths.
Those different paths can affect how sophisticated the final regulatory apparatus might be. It’s very possible that by starting to build up expertise in the way that China is doing, it might let them be a little bit more flexible by the time the final AI law comes together. Whereas there is some concern that with the EU AI Act, you’re only going to get one shot at this. You might build in some requirements, or some definitions that don’t make sense down the road, and those are harder to change.
It seems like lawmakers in the U.S. are moving slower in drawing up their own regulations. Is there a risk that, in doing so, they could cede control over setting regulatory standards to the EU and China?
The U.S. is definitely moving much later and slower than the EU and China, but I don’t think that necessarily means it’s going to get locked out of the rule setting process as the EU and China set global standards. Chinese regulations are primarily domestic facing. They will have some international ripple effects, mostly through the export of Chinese technology products or through companies that want to export to China, maybe especially in automobiles or other equipment. But, for example, China’s rules on recommendation algorithms are not setting a global standard that all companies are going to adhere to. They’re mostly about Chinese companies in the Chinese market.

The U.S. actually has a chance to learn from both the EU and China, and that is the advantage of being a second mover. The thing that we can take away most from the Chinese regulations is the way that they’ve been targeted and iterative so far. In the U.S., [Senator] Chuck Schumer — who is leading the congressional effort — is very focused on building one comprehensive piece of AI legislation that’s going to cover national security, jobs, misinformation and bias. There’s a risk in trying to do one comprehensive one-off piece of legislation that you’re either going to take forever, or you’re just never going to be able to drill down into actual policy solutions. The way that China has issued three regulations over the course of two years, with each of those regulations incorporating tools from the previous one, and then has refined and built on them, making what they hope will be increasingly refined and responsive regulations — that’s something that the U.S. could potentially learn from. Obviously we have a different political system with different values and motivations, but at the structural level. We have a chance to learn a thing or two from both the EU and China.
What is the state of AI regulation in China around areas like computer vision, facial recognition, surveillance tech etc.?
Facial recognition has gone down a different path, in that regulation there started through the courts. At first, it was something of a free-for-all when it came to facial recognition and other biometric identification in public spaces, particularly when it came to the government doing it. But you started to see people chip away at that.
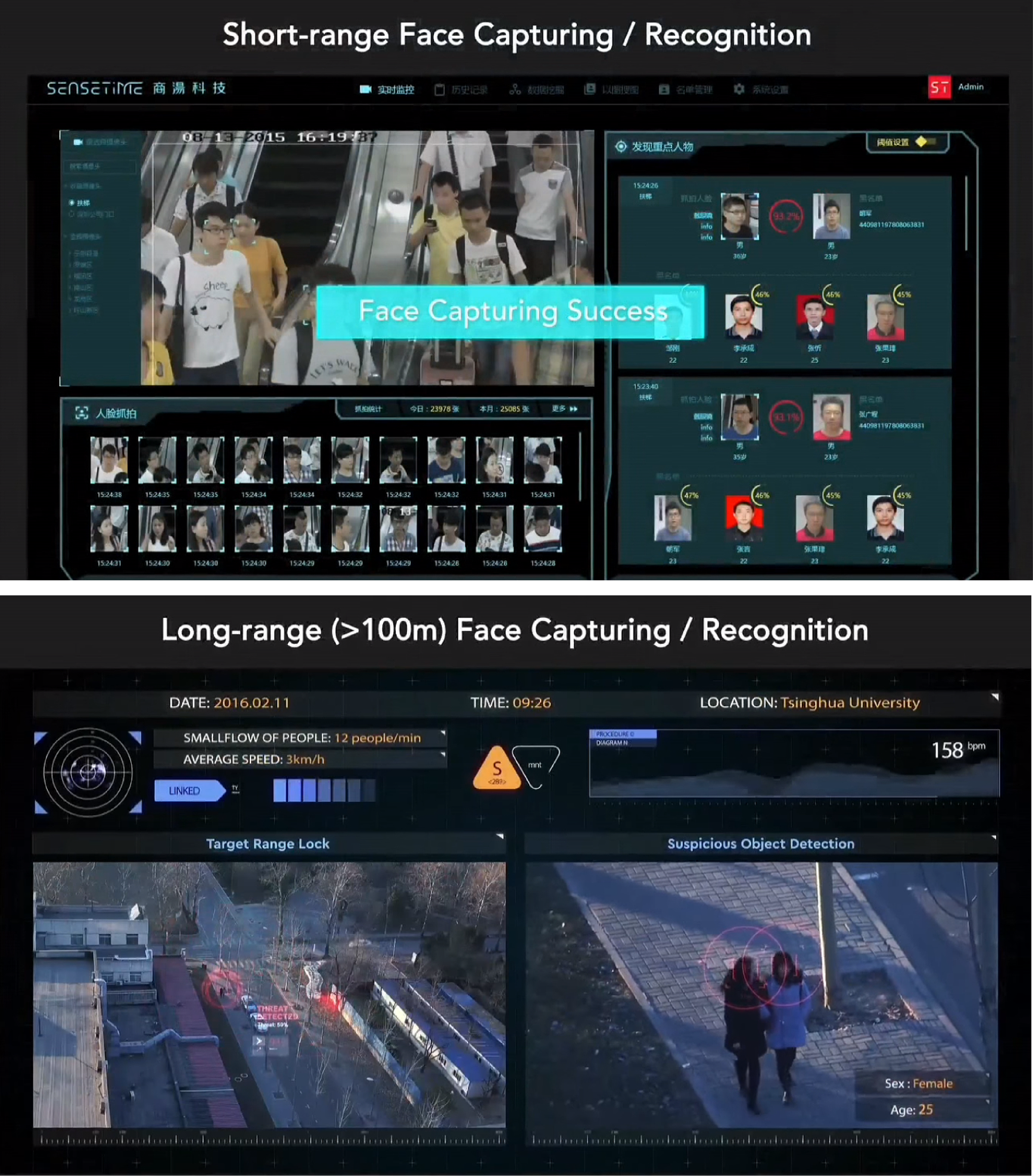
The most famous case is a law professor who went to visit a zoo in Hangzhou. The zoo required facial recognition in order to gain admittance, and he sued, saying that this requirement was unreasonable and a violation of his privacy rights. I believe he actually won that case. You’ve had one or two more cases like this, where citizens or academics are trying to use the courts as a first pass at getting restrictions built in on this. These restrictions are probably going to target private sector uses of facial recognition. When you’re thinking about China and privacy you have to have a split brain, where China can be very serious about data protection and privacy from Chinese companies, while still giving the government free rein in its own areas.
[Note: In early August, the CAC released draft rules to curb the use of facial recognition by private and commercial users. The proposed regulations would ban the use of the technology for identifying race, ethnicity, religious belief or health status without individuals’ consent, but leaves open an exception for national security. This interview was conducted before the CAC’s new rules were announced.]
Is there anything that surprised you during the course of your research?
I was surprised by how public and direct the pushback was on the draft generative AI regulation. There are a lot of internal channels by which academics and companies can give their feedback to the CAC and make their suggestions for how to improve the regulation. But in this case, it actually occurred. People did flood those private channels, but they also did have pretty public discussion and push back. Very soon after the draft was released, a group of five Chinese legal scholars issued a public letter with five changes that should be made to the generative AI regulation. You had a lot of public forums and speakers and articles, all critiquing parts of it and saying how it needs to be changed to make it more realistic. None of these are direct challenges to the party’s authority. But it’s a more public and rich debate than I probably imagined at the beginning.
With AI regulation, China is still very much figuring it out on the fly, and the government is looking around for ideas about how to do this.
It’s partly because, despite how close it is to the highly political and sensitive issue of AI competition globally, the actual domestic AI regulations themselves, don’t have deeply entrenched political fights around them. If you’re trying to do property tax reforms, you have bureaucracies and local governments and companies fighting over this for decades. Any movement in that area is going to face a ton of resistance from different parts of the system. With AI regulation, China is still very much figuring it out on the fly, and the government is looking around for ideas about how to do this. They’re looking at their own academics and thought leaders, and definitely looking abroad.
Another thing that partially surprised me is just how directly a lot of international AI governance debates feed into Chinese regulations and Chinese policy discussions. Usually the government or the regulators are not going to state outright that they’re trying to learn from Europe or the U.K. or the U.S., but when you look at the writings of the people who serve on these expert advisory committees, they’re constantly analyzing foreign regulations and figuring out the pros and cons and how they can be integrated. Or they’re using commentary on foreign regulations as a way of indirectly commenting on what’s happening in China. So the openness of the debates, and the level to which international AI governance discussions feed into that debate were positive surprises for me.

Eliot Chen is a Toronto-based staff writer at The Wire. Previously, he was a researcher at the Center for Strategic and International Studies’ Human Rights Initiative and MacroPolo. @eliotcxchen


